
kubernetesでGrafanaの表示が正しくない問題を直す
はじめに
お家 Kubernetes を構築後、どれだけメモリや cpu が使われているのか気になりPrometheus + Grafanaな環境を Helm を使って導入しました
https://github.com/prometheus-community/helm-charts
こちらの導入方法は多くの素晴らしい記事が存在するため割愛しますが、利用しているとkubectl topのメモリ使用率と
Grafanaで可視化した際のメモリ使用率が異なっていることに気づきました。具体的には下の画像の通りです
$ kubectl top pod -n ingress-nginxNAME CPU(cores) MEMORY(bytes)ingress-nginx-controller-5fcb5746fc-wcbs8 4m 97Mi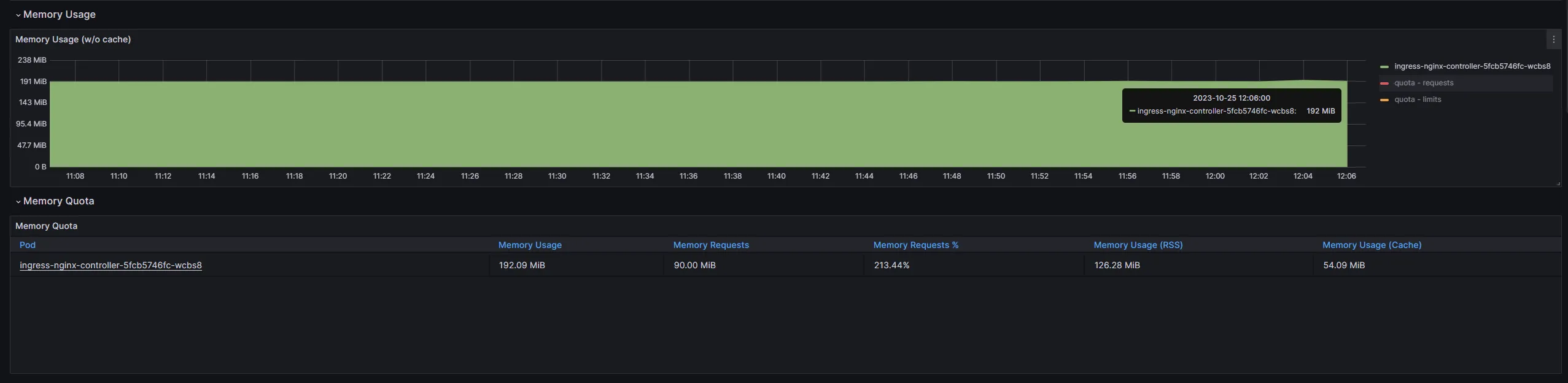
大体 2 倍程度大きく表示されています。
解決策
忙しい方のために今回の解決策だけ示すと
- 名前空間
kube-system内に、*-kube-prometheus-stack-kubeletまたは*-prometheus-operator-kubeletというServiceが複数あるか調べる
kubectl -n kube-system get serviceNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 109dkube-prometheus-stack-coredns ClusterIP None <none> 9153/TCP 3d17hkube-prometheus-stack-kube-controller-manager ClusterIP None <none> 10257/TCP 3d17hkube-prometheus-stack-kube-etcd ClusterIP None <none> 2381/TCP 3d17hkube-prometheus-stack-kube-proxy ClusterIP None <none> 10249/TCP 3d17hkube-prometheus-stack-kube-scheduler ClusterIP None <none> 10259/TCP 3d17hkube-prometheus-stack-kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 80d 👈これmonitoring-kube-prometheus-kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 80d 👈これ- 複数ある場合不要な方を消す。私の場合、
kube-prometheus-stackを導入していたのでmonitoring-kube-prometheus-kubeletを削除する
kubectl -n kube-system delete service monitoring-kube-prometheus-kubelet- 5 分ほど待つと
Grafanaに正しい値が記録され始めます
$ kubectl top pod -n ingress-nginxNAME CPU(cores) MEMORY(bytes)ingress-nginx-controller-5fcb5746fc-wcbs8 2m 96Mi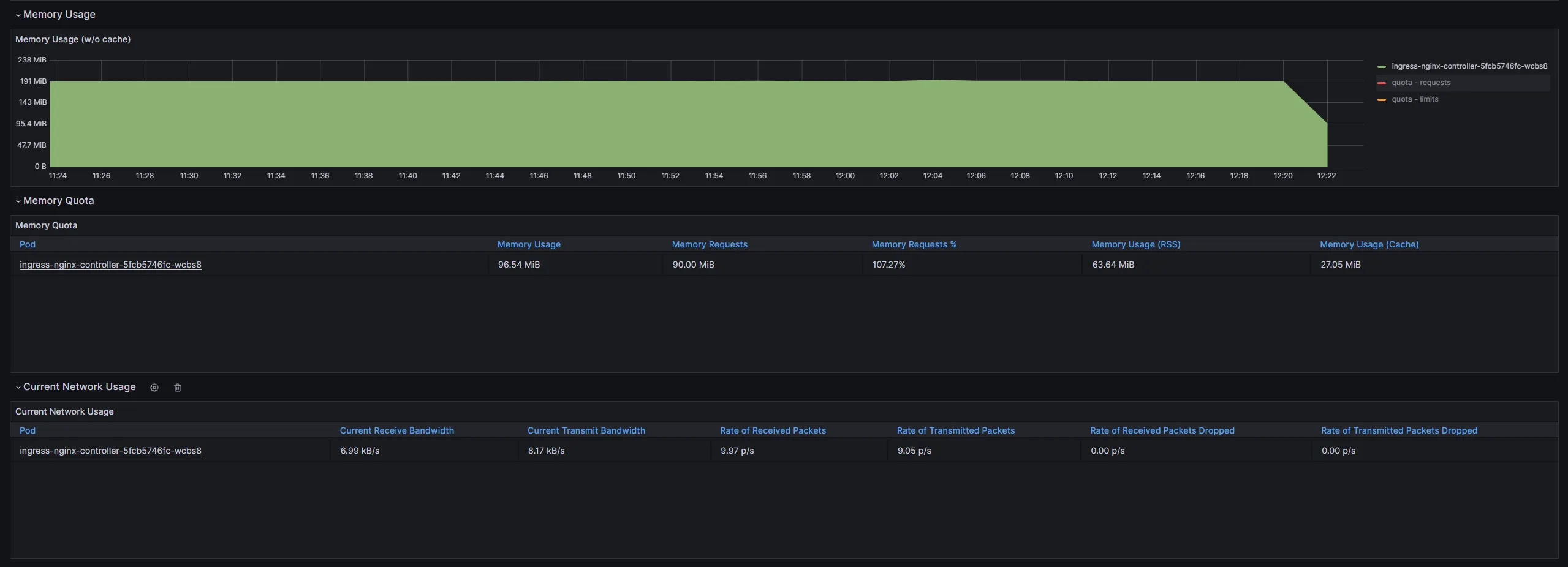
原因
基本的にすべて下の Issue に書いてありました
https://github.com/prometheus-community/helm-charts/issues/192
過去にprometheus-operatorを導入していた場合、Helm がkube-systemのサービスを削除しなかったために複数の値(今回は 2 つ)が記録され、
実際より多い値が Grafana で表示されていたようです。
実際に Grafana でクエリを発行して表のServiceを確認すると、写真が小さく見にくいですが 2 つのサービスから値が記録されていたことがわかります。
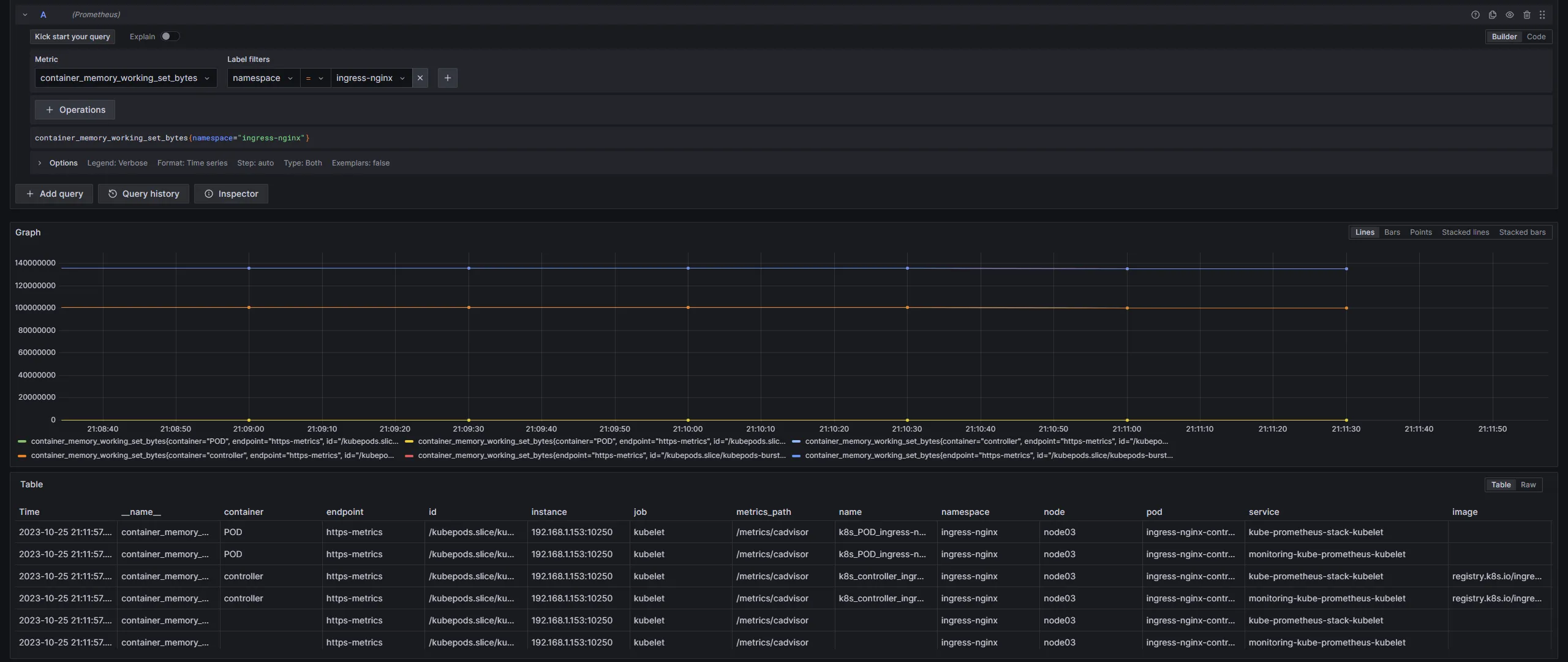
つまるところ、「過去のゴミが削除されずに悪さをしていた」というおちでした。
後書き
いくらHelmが自動でいろいろインストールからアンインストールまで面倒を見てくれる便利なツールだといっても、
何がインストールされるか、あるいはしっかりアンインストールされたかの確認が重要だということを学べました。
なかなかピンポイントな記事ですが、ここまでお読みいただきありがとうございました